Blog
Whisper Achieves 85% Accuracy on Holocaust Testimonies in Yale's Fortunoff Archive
We evaluated Whisper on 1,847 Holocaust testimonies and found 85 percent accuracy, though the model routinely normalizes raw speech and heritage spellings.
OpenAI’s Whisper achieves an 85 percent word-level accuracy when transcribing Holocaust testimonies. My colleague Christy Bailey-Tomecek and I analyzed 1,847 audio and video interviews from the Fortunoff Video Archive to see if modern automatic speech recognition could handle the complex realities of oral history. The short answer is yes, but the errors the model makes reveal a lot about how AI handles historical speech, trauma, and heritage languages. We are presenting our findings in Mallorca, Spain in May 2026 at the second gathering of the Holocaust Testimonies as a Language Resource conference.
The Fortunoff Video Archive holds over 4,500 testimonies. That is more than 12,000 hours of recorded interviews across 20 languages. Historically, turning these recordings into searchable text required dozens of human hours per video. It was simply too expensive to transcribe the entire archive at scale. We wanted to know if we could speed up the process using an open-source speech-to-text model like Whisper.
What is ASR?
Automatic Speech Recognition (ASR) converts spoken language into written text. For our project, we needed a system capable of listening to decades-old analog tape transfers and outputting highly accurate historical records.
Older transcription systems required engineers to manually tune acoustic models for specific accents or room environments. Modern deep learning tools like Whisper from OpenAI and NVIDIA NeMo handle this process end to end. They ingest raw audio files and predict the corresponding words directly. In many environments, these tools now match the accuracy of professional human transcribers.
Historical archives push these models to their absolute limits. The testimonies feature heavy tape hiss, emotional and halting speech, and frequent background noise. The speakers also regularly switch between languages. A survivor might start a sentence in English and finish it in Yiddish or Polish.
We selected Whisper specifically because its architecture was trained on 680,000 hours of multilingual data. This massive dataset allows the model to handle complex language switching without breaking down. The model easily generates a raw text output, but we still needed to measure exactly how many mistakes it made before trusting it with the full archive. We also selected it because there were available finetuned models for Hebrew and Yiddish (see below).
Calculating the Error Rate
We compared raw transcripts generated by Whisper’s large-v3-turbo model against human-edited ground truth transcripts in eight different languages. To evaluate the performance, we used a standard metric called Word Error Rate.
We cleaned the text, removed timestamps, and built a Python evaluation script using difflib to find the exact number of replaced, missed, and inserted words.
import difflib
def calculate_wer(reference_words, asr_words):
matcher = difflib.SequenceMatcher(None, reference_words, asr_words)
errors = 0
for tag, i1, i2, j1, j2 in matcher.get_opcodes():
if tag != 'equal':
# Count substitutions, deletions, and insertions
errors += max(i2 - i1, j2 - j1)
return errors / len(reference_words)We also ran the text through spaCy to analyze the parts of speech where errors occurred most often.
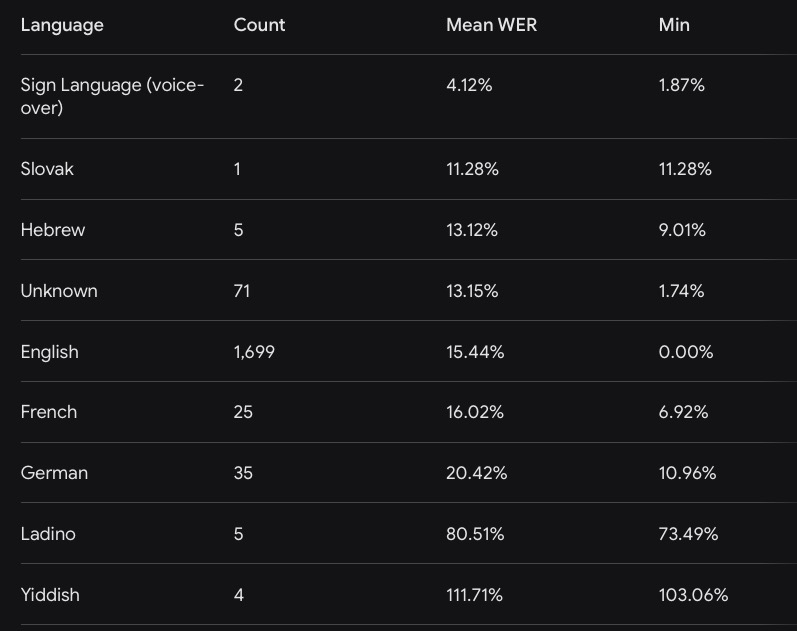
The overall results are highly encouraging. Across all testimonies, we saw a mean Word Error Rate of 15.28 percent. Over 90 percent of the testimonies hit an error rate of 25 percent or lower. In the speech recognition world, anything under 20 percent is considered quite good for conversational speech.
The Errors That Are Not Actually Errors
Holocaust testimonies are unscripted and highly emotional. Survivors pause, stutter, and cry. Our human transcription guidelines prioritize verbatim accuracy. A human transcriber writes down every “um” and explicitly marks interrupted speech.
Whisper does the exact opposite. It is optimized for readability. When a survivor says, “I was, I mean, we were,” Whisper will often just output “we were.”
When we looked at the data, missing filler words and cleaned-up interruptions accounted for a massive portion of the supposed errors. Whisper systematically dropped words like “uh” (nearly 5,000 times) and “um” (over 1,100 times). The model accurately understood the speech but formatted it for a clean reading experience rather than forensic archival preservation.
The Ladino Problem and Orthographic Erasure
Things get complicated with heritage languages. Ladino, or Judeo-Spanish, lacks a dedicated Whisper model. We tested our Ladino testimonies using Whisper’s standard Spanish model. The error rate spiked to over 80 percent, but the audio recognition was not actually failing.
Whisper correctly recognized the spoken words but automatically normalized the text into modern Spanish spelling. For example, a Ladino speaker says “katorze” (fourteen) and Whisper outputs “catorce.” Phonetically, it is accurate. Culturally and orthographically, it erases the distinct Judeo-Spanish spelling conventions.
Specialized Models for Hebrew and Yiddish
For Hebrew and Yiddish, the base Whisper model struggles with the script and historical vocabulary. We swapped it out for specialized, fine-tuned models from the ivrit-ai project.
The Hebrew model handled historical dates, specific place names like Subotica, and natural speech patterns beautifully. The Word Error Rate dropped to a highly usable 13 percent.
Yiddish presented a different challenge. The ivrit-ai model is trained largely on modern Hasidic audio and spelling conventions. The Fortunoff Archive uses the standard YIVO spelling rules. The output from the model was semantically correct but orthographically wrong for our specific archival needs. We are currently exploring resolving this by passing the raw transcripts through Gemini 3.1 Pro, which is prompted to convert the Hasidic spelling rules into YIVO rules, which improved.
Building a Better Pipeline
Whisper is absolutely viable for large-scale oral history transcription. It can drastically cut human transcription time and serve as a highly accurate first draft. However, you cannot just point an archive at an API and expect perfect historical fidelity.
If you are working with historical audiovisual materials, you need a structured pipeline:
- Run automatic language detection first to route your audio to the correct model.
- Use fine-tuned models for heritage languages whenever they are available.
- Build post-processing scripts to restore verbatim disfluencies or correct standardized spelling conventions.
The baseline technology is incredibly capable today. It just requires domain expertise to ensure we accurately preserve the linguistic heritage embedded in these testimonies.