Blog
Parsing 3.6 Million Historical Names with Small Models
We moved from expensive frontier AI to fine-tuned Qwen 3.5 models to parse historical data, achieving 96% accuracy by switching from JSON to YAML.
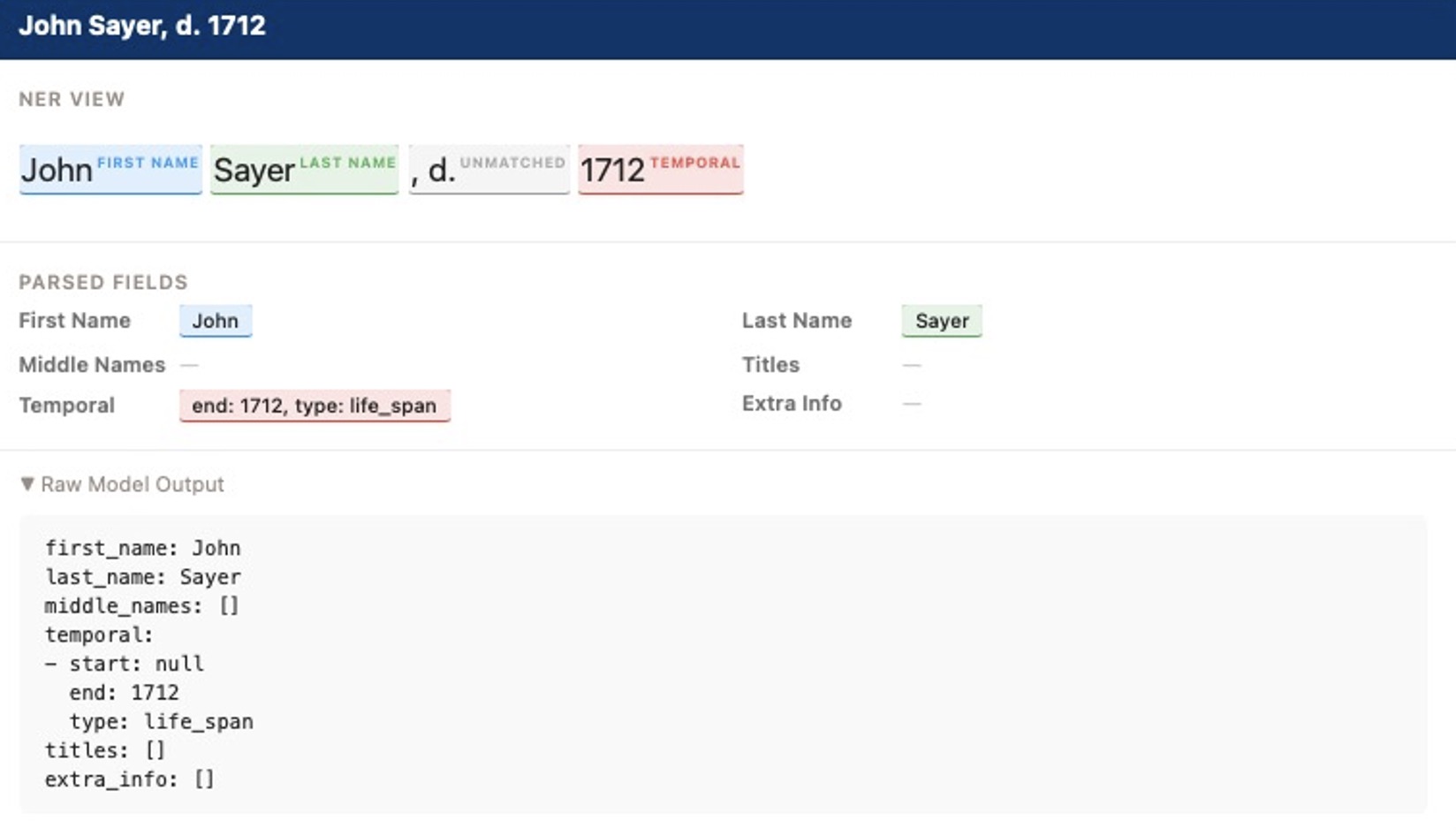
We just finished parsing 3.6 million unstructured historical names with 96% accuracy using small, open-source models.
At Yale University, our LUX platform holds over 6.3 million records for people and groups. More than 3 million of those are individual people. We know our data contains a massive number of duplicate records. We previously had no reliable way to identify these duplicates because the names were stored as flat text strings. To find matching identities, we needed to isolate specific name components like first names, last names, and life dates.
The Problem with Frontier Models
Our first attempt was passing this data to large frontier models like GPT-4 or Gemini. We quickly hit two walls. First, processing 3.6 million records through commercial APIs is prohibitively expensive. Second, the models simply failed at the task. They achieved only about 70% accuracy when pulling specific components out of highly varied historical name formats. (This was months ago. Doubtless Gemini 3.1 Flash Lite will perform better than Gemini 2.5 Flash Lite).
We needed a way to generate accurate structured data locally to keep the cost down and increase the accuracy through finetuning.
Going Small and Switching to YAML
We turned to open-source models. We started our tests on Qwen 3 and eventually settled on Qwen 3.5 for our production fine-tunes. We trained three different model sizes: 0.8B, 2B, and 4B parameters. There is also a 0.6B version for Qwen 3.
Small models offer distinct benefits. They run efficiently on local hardware and cost a fraction of the compute required by larger models. When fine-tuned, a 0.8B model can perform a narrow task like entity extraction just as well as a massive generalist model.
Initially, we asked the models to output the parsed data as JSON. We found that small models occasionally struggle with strict syntax and produce broken JSON. We switched the target output to YAML and have not had a single syntax issue since.
Here is an example of the chat format we used, where the assistant returns valid YAML inside the message content:
[
{
"content": "Parse this person name:\n\nCynthia Ponce'Hayes (born 1633), born 1633",
"role": "user"
},
{
"content": "first_name: Cynthia\nlast_name: Ponce'Hayes\nmiddle_names: []\ntemporal:\n- start: 1633\n end: null\n type: life_span\ntitles: []\nextra_info: []",
"role": "assistant"
}
]Generating 500,000 Synthetic Names
To train the models effectively, we needed high-quality examples. We built a Python script using Faker to generate 500,000 synthetic name records. You can view the full dataset on Hugging Face.
We created templates that mimic real-world cultural heritage data. These templates capture the variance in naming conventions across different time periods and geographies. We extended Faker with a custom CulturalHeritageProvider to handle localized titles, suffixes, and date qualifiers across languages.
class CulturalHeritageProvider(BaseProvider):
language_data = {
'en_US': {
'titles': ["Baron", "Countess", "Duke", "Sir", "Dame"],
'suffixes': ["Jr.", "Sr.", "III", "the Elder", "the Wise"],
'date_qualifiers': ["c.", "ca.", "circa", "about"],
'date_terms': {'born': 'born', 'died': 'died', 'flourished': 'flourished'}
},
'fr_FR': {
'titles': ["Comte", "Duchesse", "Marquis", "Roi", "Évêque"],
'suffixes': ["l'Ancien", "le Jeune", "le Grand", "fils"],
'date_qualifiers': ["vers", "env.", "ca."],
'date_terms': {'born': 'né', 'died': 'mort', 'flourished': 'florissait'}
}
# Additional locales like de_DE, it_IT, ar_SA, and zh_CN configured here
}
def __init__(self, generator, locale='en_US'):
super().__init__(generator)
self.locale = locale
self.current_data = self.language_data.get(locale, self.language_data['en_US'])
def date_term(self, term_type: str) -> str:
return self.current_data['date_terms'].get(term_type, term_type)By mapping these components into template structures, we generated half a million perfectly aligned input and output pairs.
Training on Bouchet
We trained the models for three epochs on Yale’s Bouchet computing cluster using H200 GPUs. The efficiency of the smaller parameter size was obvious immediately. A single H200 could handle a batch size of 128 without any issues.
Our fine-tuned models are achieving 94 to 96% accuracy. The minor errors we see are not hallucinations. They are typically misaligned data classifications, like misspelling a “flourished” date as “floured”.
Once training was complete, we ran inference across all 3.6 million people in LUX.
Heuristics for Merging
With our names finally parsed into structured components, we can programmatically identify duplicates. We built a tiered system to merge records based on confidence levels.
- Auto-merge: A person has the exact same first name, last name, middle initial, and shares either a birth date or a death date.
- Likely auto-merge: A person has the same first name and last name, plus two of the following match: middle initial, birth date, or death date.
- Human review: A person shares a first name, last name, and middle initial, but the dates are ambiguous or slightly misaligned.
What Comes Next
Basic heuristics are only the beginning. We are currently exploring open-source agentic models to handle the edge cases.
We are training a version of Qwen 3 with tool calling enabled. This model can connect directly to LUX and use our parsed name data to investigate potential duplicates. Instead of relying solely on name and date matching, the agent will look at the actual historical objects and collections associated with each person to determine if they are the same entity.
We will share more on our agentic workflows in a future post.